How to Perform a Comprehensive an On-Site SEO Audit
There’s never been a better time to be a white hat SEO practitioner than now. Not only has Google gotten better at identifying web spam with the Panda and Penguin updates, it’s also become more adept at understanding entities and context with Hummingbird. Gone are the days when you could just mass up on content and links on your way to the top of the SERPs. In this day and age of SEO, a more holistic approach gets the best results.
An interesting by-product of the current playing field is the resurgence of on-page and technical ranking factors. Between the mid-2000’s and April of 2012, sites that focused heavily on link building dominated the SERPs. After Penguin’s launch and the subsequent introduction of Hummingbird, Google seemed to rebalance the influence of links with on-site SEO factors. These days, analyses have shown that it’s possible to succeed in SEO without proactively building links
In this post, we’ll identify every aspect of your site that needs to be checked, analyzed and possibly tweaked for maximum SEO traction. We’ll also tackle some best practices and fixes to the most common issues. Let’s begin:
What You’ll Need
Every good SEO audit relies on data extraction, management and interpretation. To help you get all the data you need, set these platforms up for use:
- Screaming Frog SEO Spider – This is a small desktop app that allows you to crawl your site’s pages and collect data relevant to SEO. You can have the limited version for free, but the full version will cost you 99 GBP for an annual license. The free version should be enough for small and medium-sized sites.
- Google Search Console – A free service from Google that provides you with helpful diagnostic information about your site. All you need to do is sign up for the service using your Google account and verify your ownership of the site to receive data.
- Microsoft Excel – By now, we all know how vital Excel is not just to SEO but to practically any back office operation. If for some reason you don’t have Microsoft Office, Google Sheets might be your best free alternative.
Once you have these ready for use, it’s time to dig in and start assessing your site’s SEO health. Here are the main areas you’ll want to look into:
Website Availability
Availability refers to the degree to which your website can stay live and ready to accommodate visitors. Search engines consider this a very strong ranking factor simply because listings that point to dead pages offer the worst kind searcher experience possible.
Fortunately, most hosting solutions guarantee upwards of 98 percent availability per month. To check whether your site is functional most of the time or not, check the following aspects of your site:
Uptime
– Your site’s uptime can be checked with UpTrends’ free tool. Simply copy and paste the URL of your site on the blank field and hit Enter. You’ll be shown the uptime status of your site across different locales so you know where your site can be viewed from in the world.
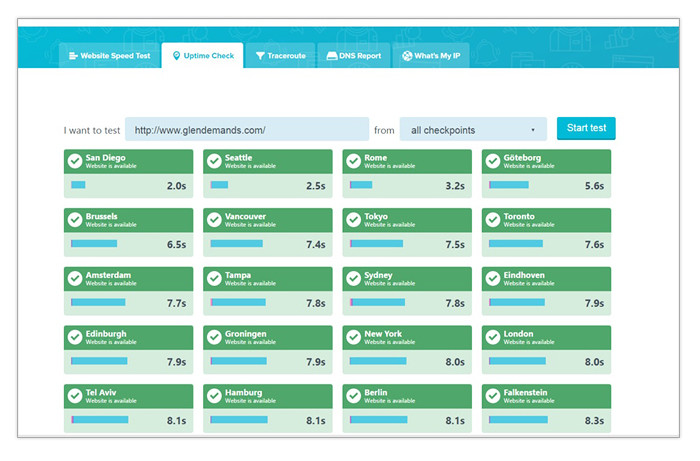
To find out if your site is having issues with uptime, check Google Search Console’s Crawl Errors report and go to the Server Errors tab. There you can see if search engines are encountering problems such as connection timeouts, connection failures, extremely slow response times and more. To address these issues, you will likely need to escalate the matter to your web developer and hosting administrator.
Crawl errors
– A crawl error happens when a search bot fails to access a page or is given an error response code by a server. In most cases, this happens when search engines try to re-crawl pages that have been deleted or have expired. To check for crawl errors, go to Google Search Console and navigate to Crawl>Crawl Errors
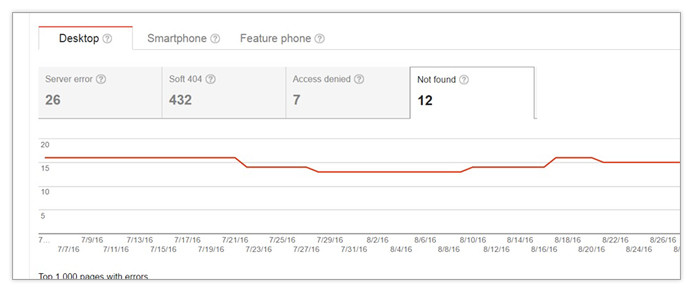
Keep in mind that it’s normal to have crawl errors in most websites. In the screenshot above, the crawl errors listed as Not Found are only 12 out of hundreds of pages. This is certainly not a big deal. However, if the number of crawl errors are at about 5% of the total pages in your site, it’s probably a good idea to start investigating and addressing them. To do that, download the crawl error report as a CSV file. You can then start examining the URLs being reported.
If you see a lot of URLs with “?” and “=” symbols, it means you’re allowing search engines to access and index dynamic pages. These pages are usually created when application servers process server-side scripts that are dependent on client-side parameters. In plain English, these are the custom pages that you see when you use filter or search functions in a website.
While most search engines can crawl and index these pages just fine, it’s not practical to let them do it. For one thing, dynamic pages eventually expire and create crawl errors. Also, dynamic URLs are almost always seen and used by just one user. That means whatever link equity and crawl budget they receive is wasted on them when it could be used more efficiently by your static pages. If you’re unfamiliar with the concepts of link equity and crawl budget, I suggest reading the resources I just linked to.
To eliminate crawl errors stemming from dynamic URL indexing, simply use your robots.txt file and disallow crawls on all pages with the question mark symbol.
If you see static pages that were deliberately deleted in the past for whatever reason, consider using 301 redirects to point users and bots to pages that have replaced them or are at least closely related to them. This fixes the crawl error and passes on whatever link equity the dead page once had.
If the deleted page doesn’t have a replacement or a contextually close cousin, you can leave it as a 404 Not Found error. Google flushes these out of its cache in time if you don’t take action on them for a few months.
Soft 404s
– A soft 404 error happens when a page displays a 404 Not Found message but gives off a 200 OK server response. This type of error can be viewed on the Soft 404s tab of Search Console’s Crawl Errors report.
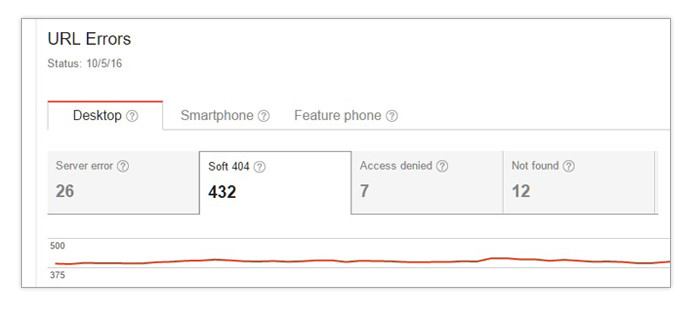
Soft 404s are usually rooted in web development errors with custom 404 Not Found messages. Having too many of these could lower your site’s overall quality rating on search engine algorithms and cause ranking issues. This type of crawl error can be addressed by having your web developer simply change the 200 IK server response to 404 Not Found while still displaying the custom message that the site owner prefers.
Accessibility and Indexing
Just because your website is live most of the time doesn’t mean that all your pages will get crawled and indexed. Neither should you want that to be the case. Smart on-site SEO is all about having search engines index pages with unique content and inherent value to searchers. This allows you to focus your site’s ranking power on the pages that truly matter.
To make sure the right pages on your site are crawled and indexed while the non-essentials stay off the SERPs, make sure to analyze each of the areas below:
Robots.txt
– The robots.txt protocol is a text file that tells bots (mostly from search engines) which of them are allowed to access a site’s pages and which ones are barred. This file can also set restrictions as to which pages and paths are off-limits. This is very important because there are pages that shouldn’t be floating around in search results. Examples include:
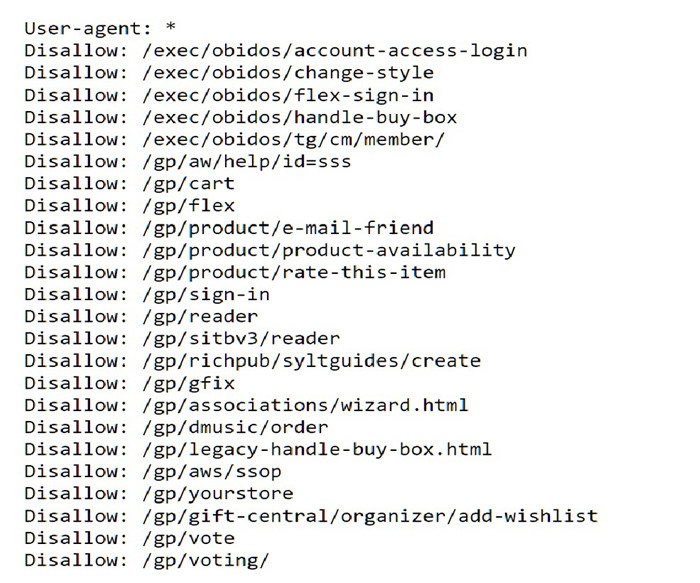
- Admin Pages – These are URLs within your site’s backend which shouldn’t be open to the public.
- Dynamic Pages – As mentioned earlier, these are pages created on a per user session basis. Dynamic pages usually have no unique content and they expire in time. Use the robots.txt file to bar bot access to this type of page and pre-empt crawl errors stemming from them.
- Checkout Pages – The string of pages that a shopper in an ecommerce site don’t have to be indexed. These are pages that are unique to that user’s transaction and are of no interest to anyone else. You can prevent the indexing of these pages by disallowing bot access to the URL path used by pages in the checkout sequence.
- Staging/Test Pages – Some webmasters use subdomains or subfolders in their sites as staging environments for pages they’re working on. Make sure unfinished work doesn’t end up on display in search results by placing a disallow parameter for these directories on your robots.txt file.
- PPC landing Pages – Some site owners running pay-per-click ads want to keep the analytics for their landing pages free of noise from sources other than paid search. If you’re in that camp, using robots.txt to block Googlebot and other organic search bots would be a good idea.
If you’re new to robots.txt, you can easily pick up how to create or edit one with this resource from Google Webmaster Central. There isn’t much to it, really. It’s mostly about knowing how to use the disallow parameter and knowing which parts of your site to bar access to.
Keep in mind that pages restricted by robots.txt are treated by search engines as non-existent. That means whatever inbound links they receive will not benefit your site and whatever pages they link to will not be found by bots. In the cases cited above, that’s fine. However, there are situations when the “noindex, follow” meta tag is a better means of excluding a page from search results and we’ll discuss that in succeeding sections.
The XML sitemap
– Though modern search engines have gotten much better at crawling and indexing webpages through links, it’s still possible for them to overlook sections of large, complex websites. To compensate for that limitation, Google and other search engines recommend using a XML sitemap.
XML sitemaps are documents in your site that contain lists of URLs pointing to public-facing pages. Sitemaps are read regularly by bots, making it easy for them to discover every page that you want to get listed on the SERPs. When put together correctly, XML sitemaps also help search engines better understand your site’s hierarchy of pages.
If you aren’t familiar with XML documents in general, don’t worry. Most modern CMS platforms come with plugins that generate and manage sitemaps with just a few clicks. Make sure the XML sitemap’s web address is submitted to Google Search Console to take full advantage of its benefits. Just be aware that having a sitemap doesn’t necessarily mean all the pages in it will all get indexed. Google and other search engines still have to make sure that the content on each page is unique and substantial before inclusion in the SERPs can happen.
You might also be interested in SEO Trends in 2016.
In its Sitemaps report, Google Search Console shows you column graphs displaying the ratio between indexed and non-indexed pages. If at least 5% of the URLs submitted aren’t being indexed, you should probably review the list of URLs to check for issues with the sitemap or the content on the pages.
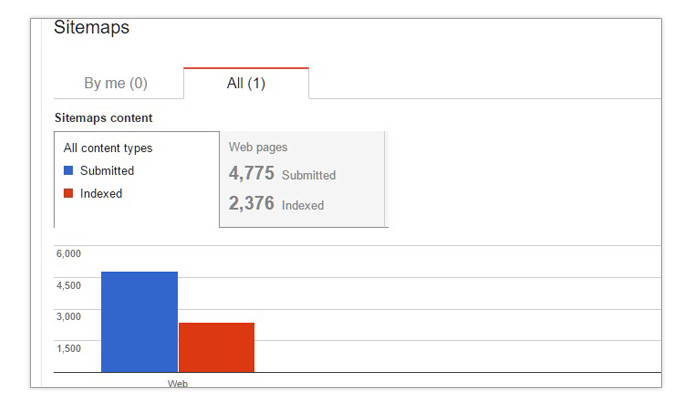
On the sitemap side, these are the factors why you may not get a 1:1 submit-to-index ratio:
Redirected Pages
– As a site advances through its lifespan, changes in its content library will inevitably happen. Some pages will become obsolete and new versions will replace them. If the new pages don’t reside in the same URLs as the old pages, webmasters will tend to use redirect protocols to guide both human users and search engine bots to the new versions of the pages.
The thing is, most XML sitemap generators will still display the old URLs while adding the new ones. This creates a redundancy due to the fact that both URLs in the sitemap eventually lead to just one page. Search engines will eventually understand the situation and stop indexing the old URL, making its presence on the XML sitemap pointless. In cases like these, it’s best to simply remove the old redirected URL.
To quickly find redirected URLs in your sitemap, use this simple process:
- Open Microsoft Excel.
- Go to File>Open
- Paste the URL of the XML sitemap you want to review. Depending which sitemap generator you are using, there could be one or more.
- Hit Enter. Excel will appear to freeze for a while, but don’t close it. It’ll eventually come to. The wait’s length will depend on the size of the file and the hardware chops of your computer.
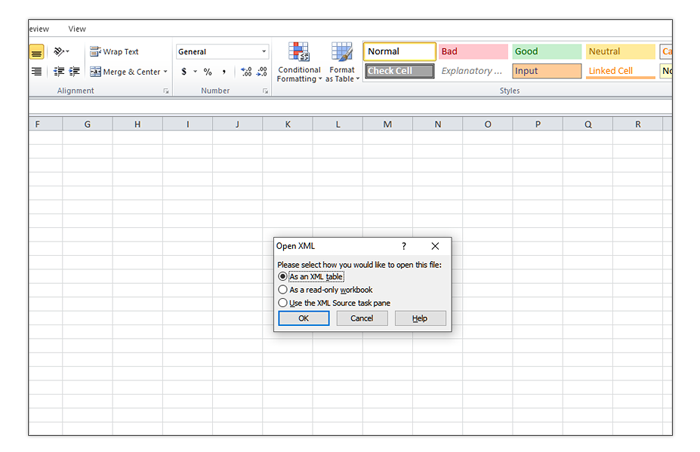
- You’ll be asked how you want to open the file. Choose As An XML table.

You’ll get a couple more dialog boxes. Just keep hitting OK and you should end up with a nice, neat table.
- In Excel, you’ll see how the XML file looks in a spreadsheet with rows and columns. Copy all the URLs onto your computer’s clipboard.
- Open Screaming Frog and go to the Mode Choose List.
- Click on Upload List and choose Paste.
- You’ll be shown all the URLs you copied from Excel and hit OK.
- Screaming Frog will now crawl all the URLs in your list and give you all SEO-related information about each page.
- When the crawl is completed, export the data to a CSV file.
- You can now sort the Status Code column from largest to smallest and see if you have 301 and 302 redirects in there.
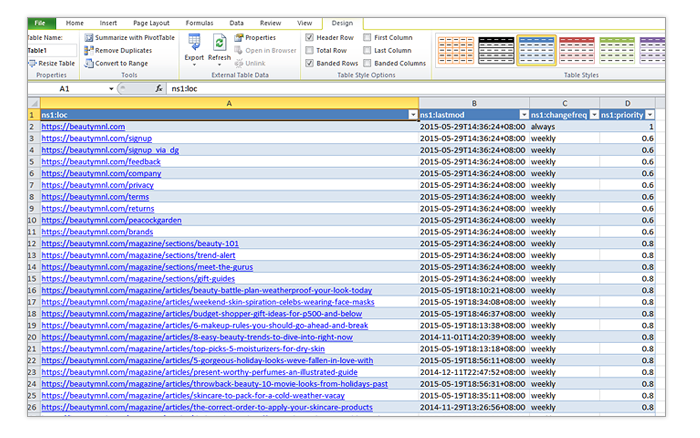
From there, you can work on removing the redirected URLs as needed.
Dead Pages
– The URLs of pages that are deleted permanently have no business being listed in your sitemap. While some sitemap generators address this automatically, some plugins don’t have the functionality to automatically remove dead pages.
When conducting your audit, make sure the XML sitemap is free of these. To do that, follow the process previously outlined for finding redirected URLs. The only difference would be with the status codes you’re looking for. Dead pages are usually coded 404 Not Found. However, there are variations which exist in the 4xx and 5xx server response code ranges.
Make sure to analyze each URL and determine whether the page really was meant to be deleted or is simply malfunctioning. For legitimate deletions, strike out the URLs from the sitemap. For webpage errors other than that, consult your web developer on how they can be fixed.
Admin Pages
– Pages that aren’t meant to be viewed by non-admin users shouldn’t be listed on your sitemap. These pages can’t be accessed by bots anyway since they will require login credentials.
If you’re a WordPress user and you see URLs with slugs like “wp-admin/edit.php?post_type=page,” you’ll want to get it off your sitemap. The same goes for backend pages in other CMS platforms.
Tag Pages
is a function where keywords can be used to group posts that mention specific terms. They’re useful to human users who want to read more about granular topics in your site. However, most SEO professionals will agree that it’s best not to let search engines index tag pages.Tag pages exist for the sole purpose of listing pages that mention the tag words and linking to them. That means tag pages don’t have intrinsic value of their own and are considered to have thin content. Also, allowing your tag pages to get indexed results in the dilution of your internal link equity flow. That is, the link equity that should be accumulating in your money pages is being distributed to dozens, if not hundreds of tags that don’t encourage conversions.
Make sure that your XML sitemap generator is configured in a way that prevents the inclusion of tag URLs in the XML sitemap. Yoast’s WordPress SEO plugin does a particularly good job at this with the Taxonomies tab in its Siteemaps settings.
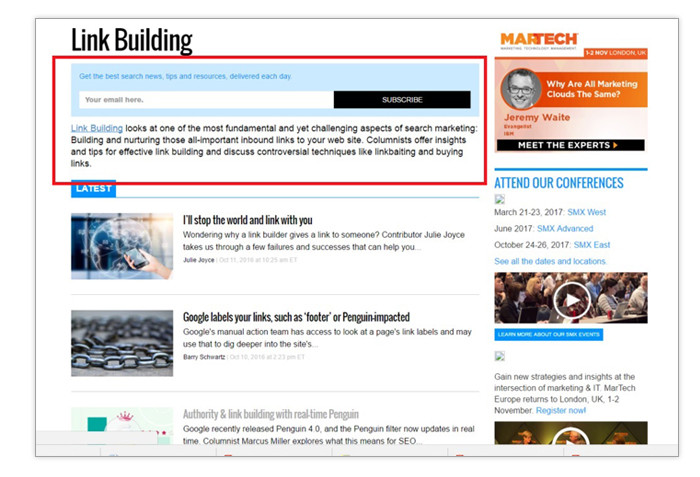
If you’re wondering why SEOs recommend preventing tags from being indexed while it’s okay to do the opposite to category pages, it’s because categories can be beefed up with content. A block of header text can be used to explain what the category page is about and what readers can expect from the posts listed under it. Sites like Search Engine Land do a great job at that:
Also, category pages facilitate the flow of link equity from the home page down to the individual blog posts or product pages. Tags don’t necessarily do that.
De-indexed Pages
– There are legitimate reasons not to have search engines index some of your pages with the noindex meta tag. Internal duplicate content and paginations of blogs and ecommerce categories are just some examples. When you decide to deindex some pages, make sure they are no longer in the XML sitemap.
The point of having a URL in your sitemap is to tell search engines to index it and pay attention to it. Having blocked content in the sitemap just contradicts that principle.
Meta directive tags
– Meta directive tags are indexing instructions within the <head> part of each page’s HTML. With meta directives, you can tell search engines to exclude specific pages from the index or to restrict certain elements of it. The most commonly used ones are:
- Noindex – Tells search engines that a page shouldn’t be indexed and listed on the SERPs.
- Nofollow – Tells search engines that a page can be indexed but the links in it should not be followed.
- Noarchive – Allows search engines to index a page and include its listing in the SERPs, but not to keep a cached copy of it in its servers.
- Nosnippet – Allows most indexing functions to happen but stops rich snippets in the SERPs from displaying.
When doing an audit, crawl your entire site with Screaming Frog in Spider mode. Filter the data to just HTML. This allows you to leave out image and CSS data which you don’t need to see right now.
Export the results to a CSV file and open it on Excel. Go to the Meta Robots column and sort the data alphabetically. This makes it easier for you to find pages with meta directive tags.
Make sure the pages with meta directives tags have the appropriate ones. Tag pages, cart pages, unoptimized categories and pages with thin or non-unique content should have indexing restrictions. Conversely, pages that you want representing you for target keywords in the SERPs should not have any restrictions caused by errant meta directive tags.
Broken links
– Broken links are links that don’t work due to one of several possible reasons. An error in typing the URL of a link or malfunctioning destination pages are two of the most common causes. Broken links are bad for user experience because they lead people to dead ends within the site. SEO can also be negatively impacted because broken links prevent the crawling of destination pages and disrupt the flow of link equity.
To check for broken links, simply crawl your website with Screaming Frog on Spider mode. When the crawl finishes, go to Bulk Export and click All Anchor Text.
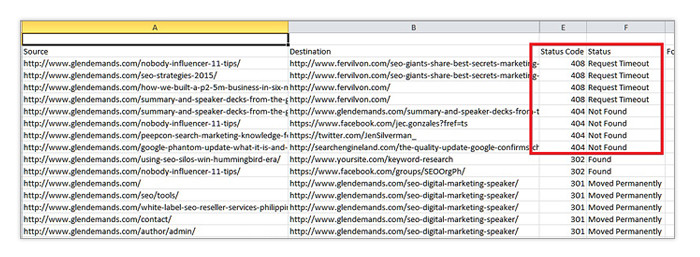
Name the CSV file as you please and open it.
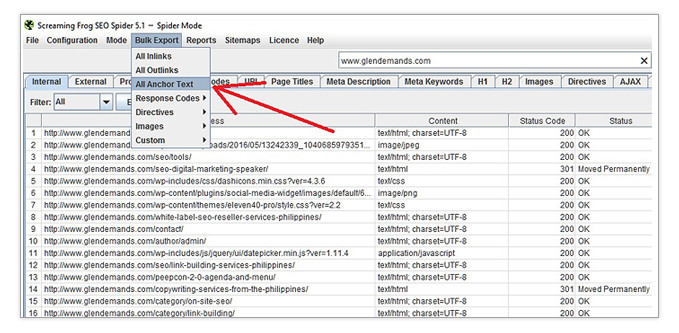
Here, you can see which pages your sites links can be found in and where they point to. You’ll also see a column labeled Status Code. Sort the data under it from largest to smallest to see which links are not currently functioning.
Orphan pages
– When a page goes live in your site but there aren’t any links to by any live pages, it’s called an “orphan.” This is an optimization issue because human users won’t be able to find these pages easily and bots would have a hard time indexing it. Even if these do get indexed by virtue of your sitemap, they won’t perform as well as it should on the SERPs because they’re deprived of powerful internal link juice.
Also read, avoiding the Big Bounce: 7 tips to check for Bounce Rate.
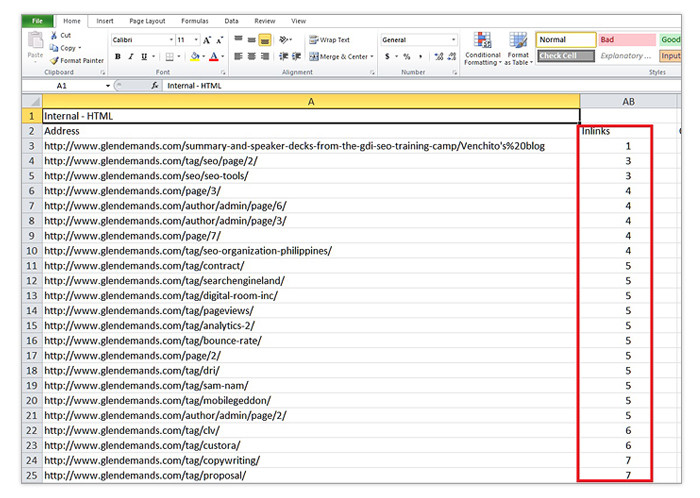
Proper internal linking is vital to your site’s organic search performance. To make sure all your public-facing pages get the internal link love that they deserve, you can run a simple test using Excel and Screaming Frog:
- Extract all the URLs from your XML sitemap/s to Excel like we did in previous sections.
- Set Screaming Frog to List mode and upload the URLs you just extracted.
- Export the results to a CSV file when the scan is finished.
- Look for the Inlinks column and sort the data from smallest to largest.
- If you see any zeroes in there, you know that the pages in those rows are orphans and must be linked to from pages in your site where it makes sense to do it.
Canonical tags
– To maintain high levels of user experience, search engines rarely show pages with duplicate content in them especially if they’re from the same website. However, not all duplications come as a result of manipulative intent or errors. Some forms of content duplication are necessary and unavoidable.
This issue is especially prevalent in ecommerce sites. Online stores can sell very similar but distinct products on different webpages. Suppose you sell shirts online and one particular shirt comes in 10 colors. You may end up having 10 different pages with roughly the same product descriptions. This could result in a few issues that will negatively impact SEO for your site:
- Search engines will choose just one of the pages to display on the SERPs. You won’t have a say on which one that will be.
- Link equity will be divided equally among the duplicate pages. That means you’ll end up with 10 weak pages instead of one strong page where the ranking power is focused.
- People may end up linking to pages which aren’t being displayed on the SERPs, wasting the precious link juice that could propel your preferred page higher on the SERPs.
If you encounter a situation like this in your audit, it’s best to check for canonical tags on the similar pages. A canonical tag is a special meta tag that can be placed in a page’s head. It serves a signal to search engines that the page is a duplicate and that there’s another page you prefer for indexing and ranking.
A canonical tag usually looks like this:
<link rel=”canonical” href=”http://www.example.com/category/product”/>
You can check the canonical tags on a site’s pages by viewing its page source. If you want to do it at scale, though, trusty old Screaming Frog will solve all your problems. Just run a crawl session and look for the Canonical Link Element column. This displays the canonical tags found on each respective page.
A proper canonical tag should point to a page that the webmaster considers the “original” among all the duplicating pages. However, you may see some sites that use the canonical tag even on pages that are 100% unique. This is usually done as a countermeasure against content scrapers. Scrapers usually use bots to copy pages at the code level. If you have pages that point canonical tags to themselves, the content-leeching site will refer back to the original and will not be indexed.
Pagination
– Pagination refers to a way of dividing and organizing category content and lengthy articles in a series of numbered pages. This helps prevent users from being overwhelmed by the volume of text and images in single, massive pages. This approach is commonly used in blogs, ecommerce sites and online magazines to make design schemes easy on the eyes. If you’re not sure what paginations look like, here’s an example from my blog:
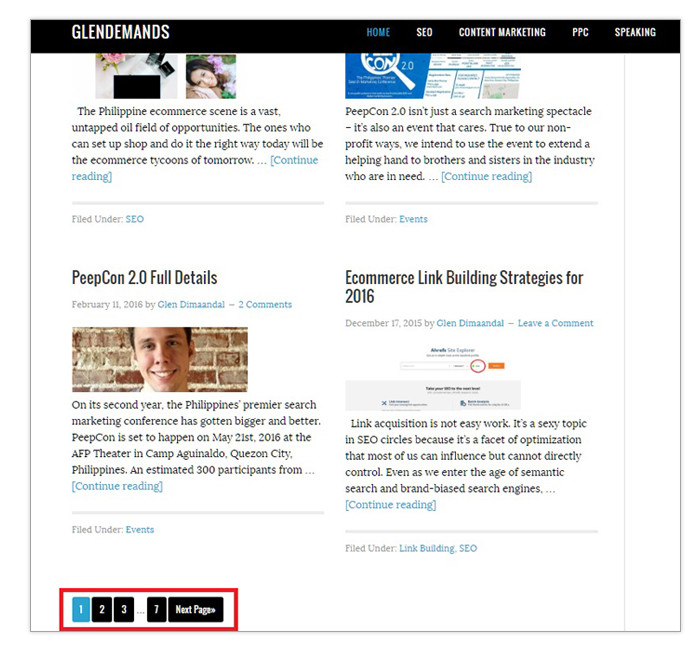
And here’s how Best Buy uses it in product categories:
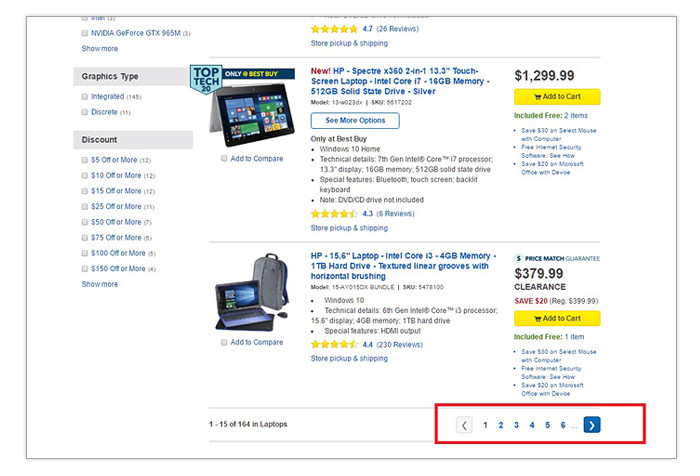
The potential SEO issue with pagination is the similarities in the content and meta data of the pages under one group. The title tag of page 1 in a category or in a blog index will likely be the same or very similar to that of pages 2, 3 and so on. This creates a content duplication problem that might have negative impacts on search visibility. Further, paginations usually have little inherent and unique value of their own. They’re just there for navigation and that might make them look like thin pages to Google
To avoid content duplication problems and to focus the link equity of your site on its category pages, you need to restrict the indexation of paginated content. You can check whether your site is allowing paginations to be indexed by going to them and viewing the page sources. If you don’t see a canonical link to the first pages in each group, noindex tags, or rel=next and rel=prev tags, your site may be handling paginations incorrectly.
You should also check if the site’s robots.txt file is blocking bot access to paginated content for good measure. If there are no parameters there to suggest any kind of restriction is going on, correct the pagination indexing issue with one of these methods:
- The Canonical Tag – Tells search engines that you only want the main page in the group indexed and that ranking signals should be consolidated in it. Have canonical links in paginations point to the first page of the group.
- The Noindex,follow tag – Allows search engines to crawl paginated content and discover pages they link to but prevents them from being indexed. To use this, simply have all paginations carry this tag in the HTML’s <head>.
- The rel=next and rel=prev tags – The rel=next tag can be placed in the HTML <head> of the first page in a series to give search engines a hint that it’s the first in a series of grouped pages. The rel=prev tag, on the other hand, tells search engines that a page is not the first in a series and that indexing/link equity credits should go to the first page. More information here on how these tags work.
Personally, I don’t recommend blocking paginations with robots.txt due to the fact that search engines won’t be able to crawl them at all. Any of the other three approaches will work fine.
Information Architecture
Information architecture is the general term used to describe how the documents in a website are organized and presented. It brings together web design and usability principles to help users access the information they need in an easy and intuitive manner.
Information architecture has plenty of synergies with SEO. The prioritization, categorization and internal linking of the content all have profound impacts on the overall visibility of your pages on the SERPs.
When auditing a site’s information architecture, make sure to crawl it with Screaming Frog both in spider and list modes. Check the Inlinks column for pages that have very few or no internal links at all. If a page that represents your site for a prime target keyword has little or no internal links,. Look into ways to add a few more. Keep in mind that the volume of internal links pointing to a page is a signal of a page’s importance to search engines.
The organization and prioritization of pages in your site also helps search engines understand topical relevance between your pages. Grouping similar product, service or article pages under a category bolsters both human navigation and latent semantic indexing. It also facilitates natural internal linking for better crawls and higher search visibility.
Implementing a silo-based information architecture is usually a great idea to boost your rankings. This is a pretty lengthy topic in its own right, so we won’t go into detail here. However, you can just follow the link and read up on a complete guide on how you can implement it.
Site Speed
Site speed has become an essential ranking signal for Google over the past few years. The rate at which your pages load has become a hallmark of good user experience as far as the search giant is concerned. Sites that have optimized their loading times now have a distinct advantage over their competitors, especially in SERPs for highly competitive keywords.
There are several factors that influence your site speed. These include:
- Server performance
- Design and layout
- Traffic volume
- File types and sizes used
- Applications running
- Browser compatibility
- Caching
- Cleanliness of code
Fortunately, Google has made it quick and easy to check for potential site speed issues. Simply go to Google Page Speed Insights and enter your homepage’s URL in the field and hit Enter.
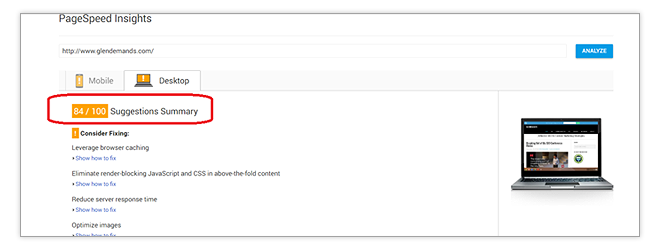
The ideal score is 85/100 or higher. Obviously, this site needs just a tiny bit of improvement to get on that level. Good thing Page Speed Insights will also provide a list of recommendations on how to boost your site speed when you scroll down. Note that most of the recommendations will likely require the participation of your web development and design personnel.
Mobile Friendliness
As mobile devices overtook their desktop counterparts in Google queries, the Big G decided that a site’s mobile-friendliness should be made a factor in its mobile SERPs. After all, there are few things as annoying as opening a search listing in your phone or tablet only to find out that you have to keep zooming the display to read the text.
Last year, Google introduced the mobile-friendly update that SEOs dubbed “Mobilegeddon.” This update favored sites with responsive and adaptive designs over sites that didn’t. This forced the hand of many webmasters to update their designs and avert the possibility of missing out on mobile traffic.
You can check if your site is mobile friendly with the Google Mobile Friendly Test tool. Similar to Page Speed Insights, all you need to do is enter your home page URL and wait for the app to process some data.
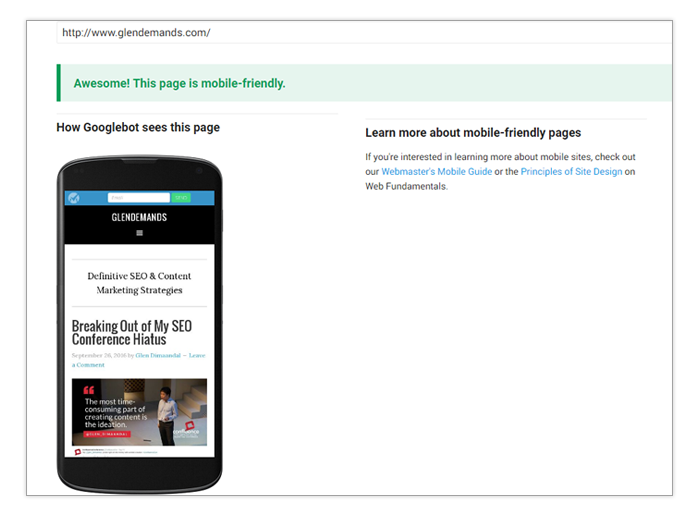
Luckily, most modern CMS platforms come with themes that are mobile friendly out of the box. If your current design isn’t mobile friendly, ask yourself and consult your company’s management on the importance of ranking in mobile SERPs to your organization. While more organic traffic is usually better, there are some companies that don’t really want or need mobile traffic. Also, keep in mind that not being mobile-friendly should not affect your site’s search visibility on desktop SERPs.
URL Structure
How your URLs are written also has an impact on your pages’ ranking performance. Ideally, your URLs should contain words that even human readers will understand instead of alphanumeric strings. Just like title tags, the URL slugs should mention the page’s main keyword and give users an idea of what it’s about.
You can check how your URLs look simply by examining your XML sitemap. A non-SEO friendly URL would look something like this:
www.example.com/2016-10-30-001
A SEO-friendly URL, on the other hand, would look like this:
www.glendemands.com/creating-useful-and-persuasive-headlines/
You can bulk check your site’s list of URLs by opening its XML sitemaps in Excel. If your site’s URLs are not SEO-friendly, it may be time to have a conversation with your developers about it. This can be quite a project for bigger sites, but it has to be addressed sooner than later. Correcting an issue like this would likely involve the creation of SEO-friendly versions of all your site’s pages. The old ones with non-friendly URLs will then have to be 301 redirected to the new ones.
Secure URLs
Using secure (https) URLs was made a ranking signal a couple of years ago by Google. According to the search giant, data integrity and the security of online transactions were the primary reasons for rewarding sites that use encryption. While the ranking benefits seem to be minor, having the smallest advantage can separate your site from the rest of the pack in highly competitive SERPs.
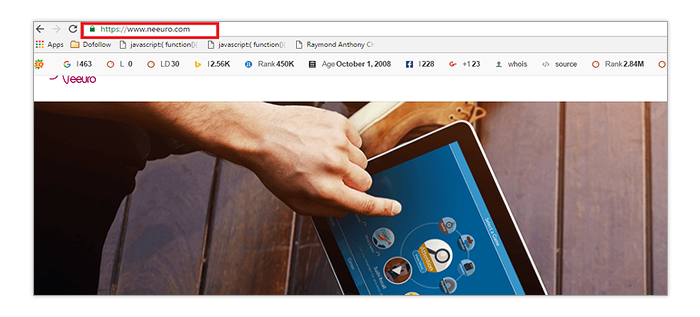
Checking whether a site uses secure URLs or not requires no specialized tools or processes. Simply check out the URL field in the browser and look for the green pad lock icon. If it isn’t there, it means you are either not using secure URLs or it’s not set up correctly.
Title Tags
The title tag is the most powerful on-page ranking element to this day. This is the text that’s present in the HTML header of every webpage but is invisible within the browser window. Title tags are used by search engines as the listing headlines for pages they index and display in their SERPs.
Well-optimized title tags possess most, if not all, of the following qualities:
- Captures the essence of the page in 60 characters or less (including spaces)
- Mentions the main keyword at least once
- Mentions the most important keywords as early in the field as possible
- Is not stuffed with slight permutations of the same keywords
- Is not a duplicating or very similar to title tags in other pages
- As much as possible, mention your brand towards the end of the title tag
You can check the title tags of every page in a site easily by using Screaming Frog. Simply run a session and check the Title 1 column. Next to it is the Title Tag length which gives you the character count of each page. Sort this column from largest to smallest to find any excessively long title tags quickly.
Duplicate title tags can be found with ease in Google Search Console. Just go to the property and check the Search Appearance>HTML Improvements section. There you can see any instances of duplication and figure out the root causes.
Title tag duplications are usually a result of one of the following:
- Web developers using the same title for every page during pre-launch
- CMS-generated duplicate pages
- Product category and blog index pagination
- Different SKUs of the same product found in different pages
Developer errors need to be manually addressed with rewrites. The rest can be dealt with using canonical tags on duplicate pages pointing to the original page that you want representing you on the SERPs.
META DESCRIPTIONS
Meta descriptions haven’t been a Google ranking factor for a while now. You can practically leave them blank and Google would just choose the most relevant text in your page to display on the SERPs. That, however, doesn’t mean you should.
You see, even if meta descriptions don’t directly impact rankings like title tags do, they still influence how much organic traffic you get. Writing concise, informative and enticing descriptions can increase click-through rates in the SERPs and lead more people to your pages. What’s more, it’s widely believed that organic search click-through rates are viewed as an important usage signal that nominally influences your listing’s position in the SERPs.
When performing an audit, make sure that each public-facing page has a proper meta description written for it. Good meta descriptions possess the following attributes:
- 160 characters long or shorter
- Must mention the main keyword at least once.
- Must mention the brand name at least once.
- Should be an effective summary of the page’s content.
- Should have a call to action if space permits it.
As the case is with title tags, meta description data from your site can be extracted easily using Screaming Frog. Make sure all indexable pages have this field filled out with unique material that complies with the list of best practices above.
And like title tag duplications, redundancies in meta descriptions can be detected with the help of Search Console. They also happen for the same reasons as the ones listed for title tags. The drill remains the same: write descriptions for indexable pages that don’t have them, rewrite ones that look like they were pasted to several pages for the sake of having them there and use canonical tags for cases of absolute duplication.
Schema Markups
Structured data markups from Schema.org’s vocabulary help search engines better understand certain parts of your pages better. Formats such as Microdata and RDF can help Google and other search engines recognize review scores, prices, author names, dates and more so they can display them in your search listings as rich snippets.
It’s generally a good thing to have rich snippets along with your listings. This information usually makes your listings more eye-catching and therefore more likely to get clicked on. To check if your site is using Schema markups correctly (if at all), check out Search Console’s Search Appearance>Structured Data report. If you have Schema markups functioning properly, you should see something like this:
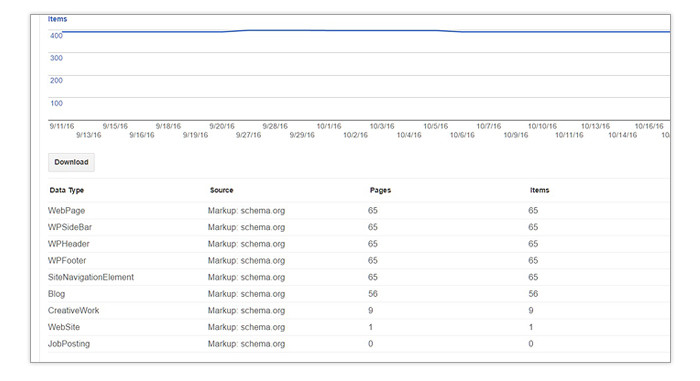
Now, Schema implementation isn’t always the easiest thing to do. You need to tinker with how your site’s code works to do it at scale. In most cases, your site’s web developers will need to get involved to make sure it’s done correctly.
Fortunately, some theme makers for popular CMS platforms have introduced skins that have Schema built into them. The Genesis Framework for WordPress is a good example of that.
If you aren’t much of a coder and you’re struggling to get help from your site’s devs, an alternative route would be to use Search Console’s Data Highlighter tool. This is a point-and-click solution for helping Google understand your essential HTML elements. However, it has its limitations so think of it more as a band-aid fix than a lasting solution. More on the tool in this video from Google.
User-visible Content
Your site’s meta data is only part of what search engines analyze when they weigh on-page ranking elements. What’s visible to users when they load your pages also influences how your site ranks for its target keywords.
The following are on-page ranking elements that you need to check when auditing a site:
Headline Text
– Your page’s headline text weighs heavier than regular body text when it comes to SEO. That’s because the text that’s formatted with H1, H2, H3 and other sub-headline tags allow you to segment your content into different topic sections. This helps readers find the info they’re looking for more easily., It also helps search engines get a better idea of what keywords are really being emphasized in the content.
SearchMetrics did a ranking factor study last year and determined that H1 text is still strongly correlated with good rankings. As a rule of thumb, make sure that most of your public-facing pages have H1 text that mention the page’s main target keyword. This is as much about good, old-fashioned labeling as it is about SEO best practices.
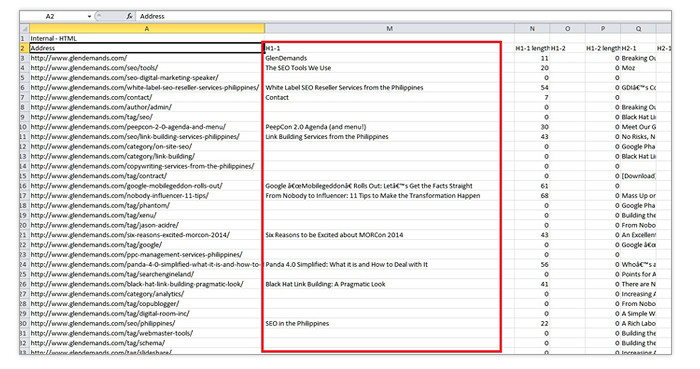
To check which of your pages have H1 and H2 text, simply run a Screaming Frog session for the URL list that you extracted from your XML sitemap. Export the crawl data to a CSV file and open it with Excel. There will be a column labeled H1-1. Sort the data from A to Z to see which pages don’t have H1 text. Investigate why this is the case and write H1s as needed.
Content Length
– While longer content is not necessarily better, Google seems to favor pages with more breadth in its rankings. Referencing the SearchMetrics study again, pages that have 800 words or more in their body tend to outperform their shorter counterparts. This is likely because Google wants to provide users with the most complete answers possible to satisfy the intent of their queries.
A Screaming Frog data sheet will have information on the length of the content in each page that was crawled in a session. Go to column Z and sort the data from smallest to largest. You can see here which of your pages have the thinnest text content easily so you can address it immediately.
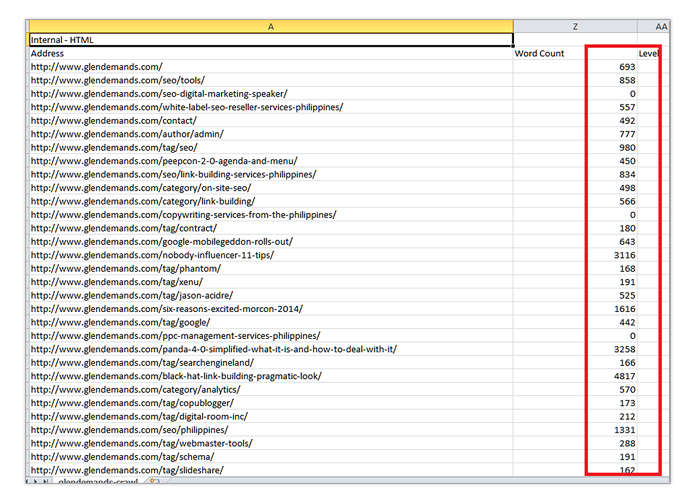
Keep in mind that SF’s word counts include every part of the page including headers. footers and sidebars. This means that the numbers you get will not reflect just what’s in the main body section – it counts words in other parts of the page, too.
Also, content length is not a hard and fast rule that should compel you to try and hit 800 words in every [age you publish. Contact Us pages or dictionary webpages are meant to be short. The same goes for news briefs. Google will still index and rank these pages because it’s smart enough to understand that some queries can be addressed with very brief answers.
Apply the content length best practices more to blog posts and informational webpages. You can also apply this to category and product pages by adding text blocks above the fold like this:
Above the fold text is generally given the most weight out of all the body text found in a page, so leverage it by mentioning your main keyword at least once here. Then supplement it with a block of text meant more for SEO at the lower sections of these pages where they don’t get in the way of site design:
Content Duplication
– In earlier sections, we discussed how non-spammy duplications of pages within your domain could create indexing and ranking issues for your site. In this section, we’ll focus more on the type of duplication that happens between two or more domains and how you can address them.
In the vast majority of cases, webmasters would be appalled by the idea of taking content from another website that they don’t own and slapping it on theirs. Not only is the act unethical, it’s also an infringement of copyrights and is therefore illegal. However, this does happen from time to time for completely legitimate reasons.
For instance, online retailers often sell products that they did not create themselves. Each of these products will have specifications and descriptions from its own sites or catalogs. Far too often, ecommerce operators will not have the time, will and manpower to write their own unique product descriptions and the copy is used by different sites that carry the product. This creates the inter-site duplication and it can sometimes prevent a site’s pages from being indexed and ranked.
While in the subject, read SEO Conversion for e-commerce sites.
Another example would be with news sites. More often than not, a news site will carry news from agencies like AP, AFP, Reuters, etc. These organizations have correspondents in practically every location on the planet who cover different beats. Since smaller and more localized news sites don’t have this capability, they often run stories from these agencies for a fee. When several news websites get their news from the same source, possible cases of duplication may occur. The very same can happen when news sites publish raw press releases exactly as they got them.
You can check for inter-site content duplication using a tool called Copyscape. It’s more of a plagiarism detection tool but it can also work for ecommerce site copy. It does have its limitations, so you may have to pay for its premium service to get better experiences with it. Alternatively, you can just paste blocks of text in your product and article pages on Google and see if exact same results are found on other sites.
If your site uses boilerplate product descriptions, consider putting together a list of priority products that you’ll write unique copy for. These should be your top-selling items or the ones that you can see becoming big sellers. The pages that you can’t create unique content for can be de-indexed for now with the “noindex,follow” meta tag. You can come back to them later and write new copy when your writers are done with the items in the priority list. This helps keep your indexing percentage high and focuses your link equity only on the pages that won’t be filtered out of the SERPs.
If you’re running a news site, avoid the habit of posting stories from news agencies and press releases exactly as they were when you received them. Make sure that you have a professional news writer who can extract the facts from the source material and write it in a unique way in line with your publication’s style guide. Try to add supplementary information that give readers better context on the story that you covered. Keep in mind that you can copy some parts of a story or an article as long as you provide proper attribution and ensure that the greater part of your article is your own material.
Site Layout
– Site design was not thought of as a significant SEO factor in the past but all that has changed when Panda and Hummingbird came along. If we’re to believe the Google Quality Rater guide, it’s only logical to assume that site design has an impact on how well webpages perform on Search.
Google has long discouraged the use of design schemes that mislead or confuse readers into clicking and reading on-screen objects that they’re not necessarily interested in. Best practices suggest that the main body of each page needs to be easily identifiable and must be intuitive enough to facilitate comfortable skimming. Still, some shady websites don’t understand this and end up going with design templates that result in poor user experiences.

Take this site for instance. At a glance, it’s hard to see what it’s really about because the body occupies only about 20% of the real estate on display. The rest are sidebar navigation links and promotions that are easy to mistake as being part of the body.
There’s nothing wrong with using elaborate designs and running promotions on your site is a generally acceptable way to monetize your site. However, make sure to balance this out by making sure your page’s core content is not overpowered by other elements. This helps you improve your site’s usage signals such as bounce rates, pages per visit, times on site and more which can help boost your search rankings.
Ad Placement
– Opening up your site to advertisers is a legitimate to monetize your traffic. Search engines understand that every website is a media outlet in its own right and it’s perfectly fine to extract revenue from your efforts.
However, it’s also a fact that not all forms of online advertising are considerate to the site’s users. Some ad types can frustrate users by obscuring the path to what people are looking for in a webpage. Other ads may deceive users by tricking them into clicking links that lead to advertiser pages even when users are not inclined to do so.
When performing an audit, make sure to pay attention to how ads are positioned in each page that they’re found in. Observe whether they’re clearly identifiable or whether they’re being made to blend with the page’s non-sponsored sections. Banner, sidebar and even footer ads are generally fine. The moment they’re positioned within a page’s body and not labeled as advertisements, you can raise a red flag.
You might like more information on Google Authorship and SEO.
Also, make sure that ads have the rel=Nofollow attribute so they don’t pass along equity to advertiser pages. Treat affiliate links the same way. Search engines may suspect that your website is running a manipulative link scheme once they detect that non-editorial links are helping boost pages that didn’t earn those links.
Images
– Your site’s images play an important role in its search visibility. Ranking factor studies have consistently shown that sites which showcase a healthy balance of text and image content perform better in the SERPs than pages which contain just text or images. Your site’s images can also draw plenty of organic traffic thanks to Google’s Image Search mode.
Well-optimized images possess most — if not all the following qualities:
- Descriptive file names in plain human words
- Image alt text
- Small file size
- Appropriate file formats (PNG, JPEG, GIF)
- Listed in image XML sitemap
- Caption below the images (used mainly in blogs and news sites)
To check if your images have SEO-friendly file names and whether or not they have alt text, run a Screaming Frog crawl of your site. Go to the Images tab and you’ll be shown image data pertinent to SEO.
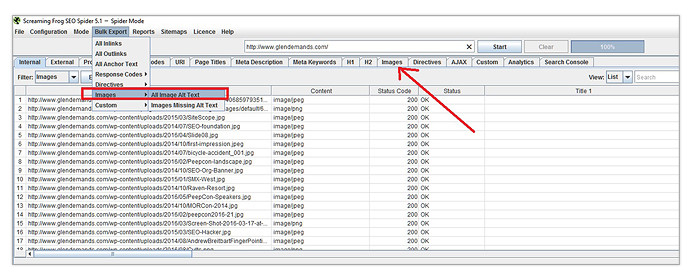
Click on the Bulk Export menu item and navigate to Images>All Image Alt Text and OK the export. Name the CSV file as you please and open it. You should see information on the image file’s address path within your domain as well as the page where it can be found.
Check the URL slugs of the emails to see their file names. Edit those when you see that the file names are not descriptive of what the image depicts. This, of course, can be quite a monumental task for large websites. The best way to approach it is to set aside some time for a small team to do it. This is not the highest of SEO priorities, so you shouldn’t exhaust a lot of time and effort on going after it immediately.
Each image’s alt text info will also be available in the sheet you just exported. Check which ones don’t have this attribute. Write new ones for those that don’t and edit the ones that contain non-descriptive content.
Hyperlink Attributes
– The links in your site and their attributes can either help or hurt your search visibility depending on how you treat them. As Google becomes smarter with spammy link detection, you’ll want to make sure that you’re following all the best practices in this department.
Good linking practices include:
- Adding the link Alt attribute
- Using non-exact match anchor text for external links
- Adding the rel=Nofollow attribute to external links which are not editorially given (ads, affiliate links, etc.)
- Not linking to pornographic, weapon, drug, violence-oriented sites
- Using keyword-infused anchor text for internal links
To have a comprehensive view of how your site links both internally and externally, perform a Screaming Frig crawl. Once it finishes, go to the Bulk Export menu and click on All Anchor Text. Export the data to the a CSV file and open it on Excel.
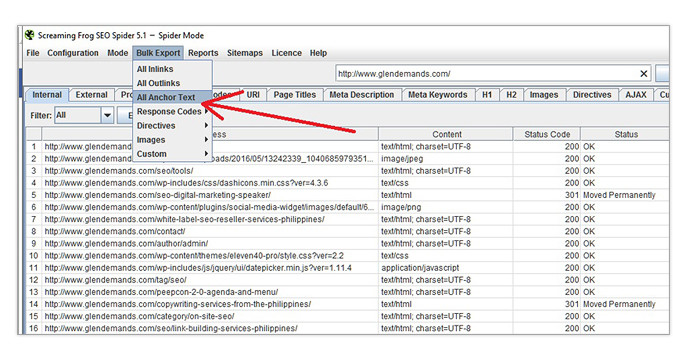
The sheet will contain data on which pages the links are found on and what their destination pages are. More importantly, you’ll be shown their respective anchor text and alt texts. At the rightmost side is the Follow column. It will only contain the words TRUE or FALSE. TRUE signifies that the link is dofollow and FALSE would mean that it has the rel=Nofollow attribute.
Link Alt text work like Alt text for images. They appear on screen when a user mouses over a link and they contain information on what the user can expect from the destination page.
iFrames
– An iFrame is basically a webpage embedded within a webpage. YouTube videos, SlideShare decks and PDFs embedded within pages are prime examples. iFrames are considered a norm on the web these days, but there seems to be a little confusion as to how they affect SEO.
Generally, you don’t have to worry about using iFrames in a site. There is no truth to the claims that suggest iFrames are bad for SEO. However, you just need to be aware that each iFrame has an outbound link that will channel link equity from your page to another. You also need to be aware that your site gets no credit for the content in the iFrame. Advanced search engines like Google are able to follow the iFrame back to the source page and give that page the credit as opposed to yours.
When performing an SEO audit, gather a list of pages with iFrames and review them one by one. While looking at each, ask yourself whether the page is there just to host the iFrame or if it provides enough intrinsic value on its own to warrant its existence. This happens to be the same principle that Google uses to assess whether a page has thin content or not.
That’s Matt Cutts explaining the theory behind thin content. Notice how I was confident enough to use iFramed content because this post has a lot of intrinsic value in itself. J Anyway, having the content of your page perceived as thin will likely mean it won’t be indexed or it’ll perform poorly in the SERPs. You can avoid this by adding supplementary content such as contextual anecdotes, background facts and transcripts to videos.
Malware and Hacks
Unless you’re a real Internet creep (or crook), the last thing you’ll put in your site is malware that infects our visitors’ computers. Google and other search engines have advanced algorithms that can detect malware and flag the sites that host them. Domains found with malicious software often suffer ranking declines until the issue is resolved.
And while you may have no intention of adding malware to your own site, hackers or nasty competitors might be inclined to do it for you. Though it’s a rare phenomenon, sites that are dominating SERPs in competitive industries have usually had close calls with hackers at one point or another.
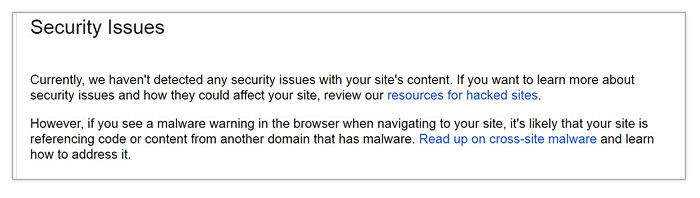
You can detect malware easily by with Search Console. The platform lets you know through a message that there’s malware in your site as soon as it detects it. You can also check for malware on your site through Search Console’s Security Issues report. Of course, prevention is always better than cure. Beefing up your site’s security is always the best way to avoid ever having this issue.
Conclusion
A proper and thorough on-site SEO audit is a crucial phase of every successful SEO campaign. It lays the foundation that will either amplify or nullify the effects of your content creation and link acquisition efforts later on. However, don’t think that an audit is a one and done type of deal. To keep your site performing well in the SERPs, I recommend doing a re-audit annually or bi-annually.